在数据库查询中,count(*) 和 count(1) 是两个常见的计数表达式,都可以用来计算表中行数。
很多人都以为 count(*) 效率更差,主要是因为在早期的数据库系统中,count(*) 可能会被实现为对所有列进行扫描,而 count(1) 则可能只扫描单个列。
但事实真是如此吗?
执行原理
先来看看这两者的执行原理:
count(*) 查询所有满足条件的行,包括包含空值的行。在大多数数据库中,count(*) 会直接统计行数,并不会实际去读取每行中的详细数据,因为数据库引擎会自行优化该计数操作,以提高执行效率。
count(1) 也是计算表中的行数,这里的 1 是一个常量,只是作为一个占位符,并没有实际的含义。与 count(*) 类似,数据库引擎也会对 count(1) 进行优化,以快速确定表中的行数。
count(*) 和 count(1) 的 性能差异
再说性能,在大多数数据库中,其实 count(*) 和 count(1) 的性能非常相似,甚至可以说没有区别,这是因为大多数数据库引擎对这两种计数方式进行相同的优化,并没有明显的执行效率上的差异。但是在特殊情况下可能会有细微的差异,造成这种差异的原因通常有以下几种:
1. 数据库引擎的差异
不同的数据库引擎可能对 count(*) 和 count(1) 采取不同的优化策略,这在某些情况下可能会导致两种计数方式的性能差异。例如:
-
- SQL Server:在某些版本的 SQL Server 中,
count(1) 在特定的查询计划中可能稍微快一些,但这种差异通常微乎其微,只有在处理非常大的表或复杂查询时才会显现出来。 -
- MyISAM 引擎:在不附加任何
WHERE 查询条件的情况下,统计表的总行数会非常快,因为 MyISAM 会用一个变量存储表的行数。如果没有 WHERE 条件,查询语句将直接返回该变量值,使得速度很快。然而,只有当表的第一列定义为 NOT NULL 时,count(1) 才能得到类似的优化。如果有 WHERE 条件,则该优化将不再适用。 -
- InnoDB 引擎:尽管 InnoDB 表也存储了一个记录行数的变量,但遗憾的是,这个值只是一个估计值,并无实际意义。在 Innodb 引擎下,
count(*) 和 count(1) 哪个快呢?结论是:这俩在高版本的 MySQL 是没有什么区别的,也就没有 count(1) 会比 count(*) 更快这一说了。 -
另外,还有一个问题是 Innodb 是通过主键索引来统计行数的吗?
如果该表只有一个主键索引,没有任何二级索引的情况下,那么 count(*) 和 count(1) 都是通过通过主键索引来统计行数的。
如果该表有二级索引,则 count(*) 和 count(1) 都会通过占用空间最小的字段的二级索引进行统计。
2. 索引的影响
如果表上有合适的索引,无论是count(1) 还是 count(*) 都可以利用索引来快速确定行数,而不必扫描整个表。在这种情况下,两者的性能差异通常可以忽略不计。例如,如果有一个基于主键的索引,数据库可以快速通过索引确定表中的行数,而无需读取表中的每一行数据。
实战分析
话不多说,下面我们通过实验来验证上述理论:
第一步:创建表与插入数据
用 Chat2DB 给我们生成一个创建表的 sql 语句,直接用自然语言描述我们想要的字段名和字段类型即可生成建表语句,也可以生成测试数据。
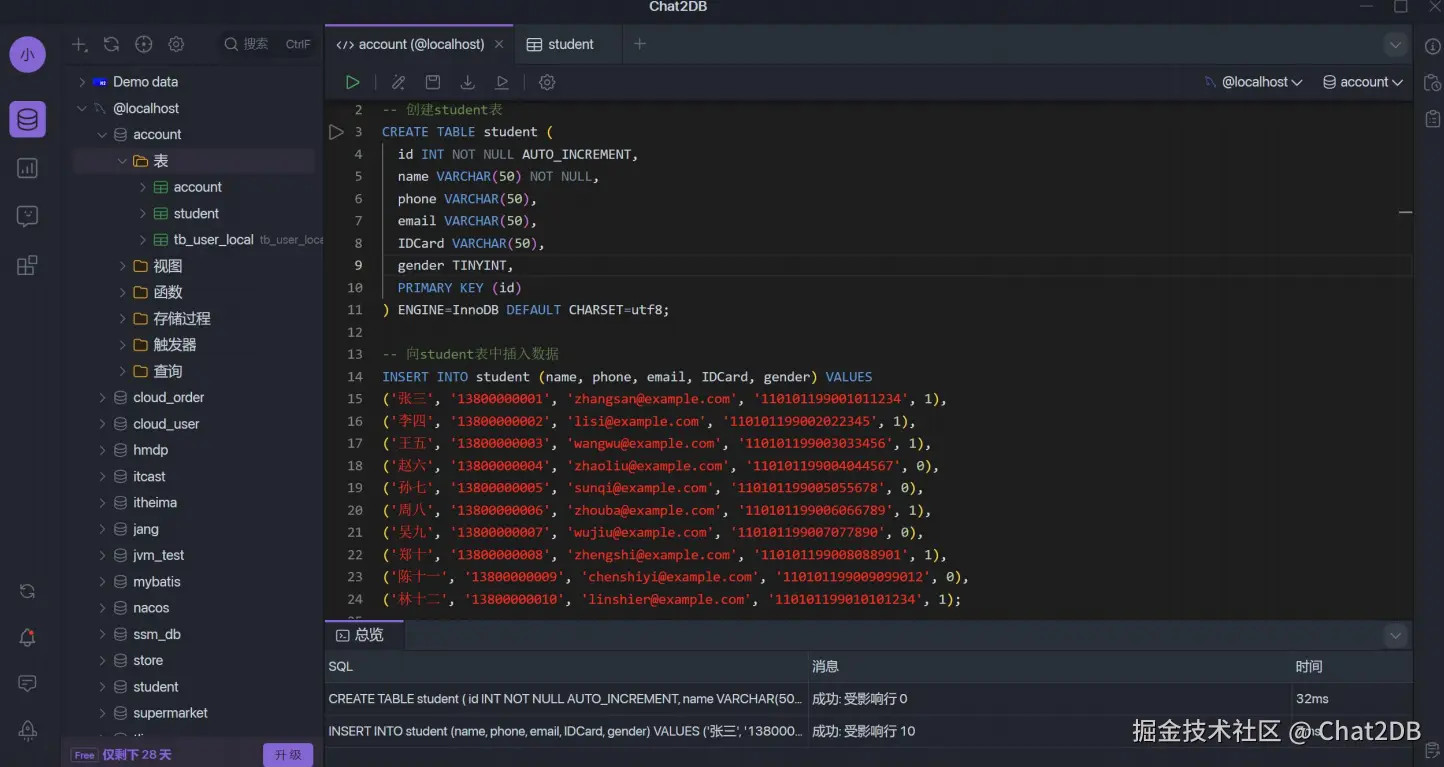
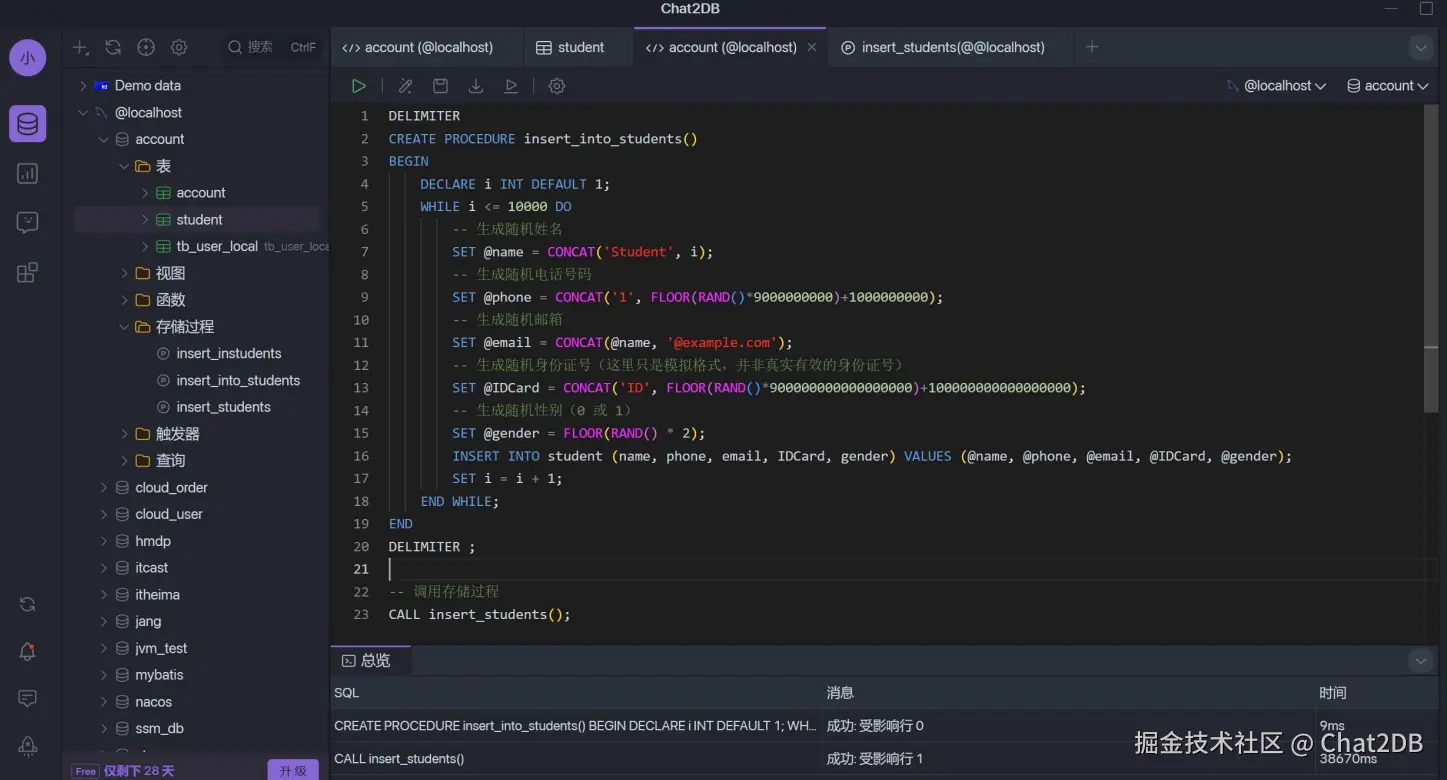
然后用存储过程向 student 表中插入两万条测试数据。(存储过程执行两次)
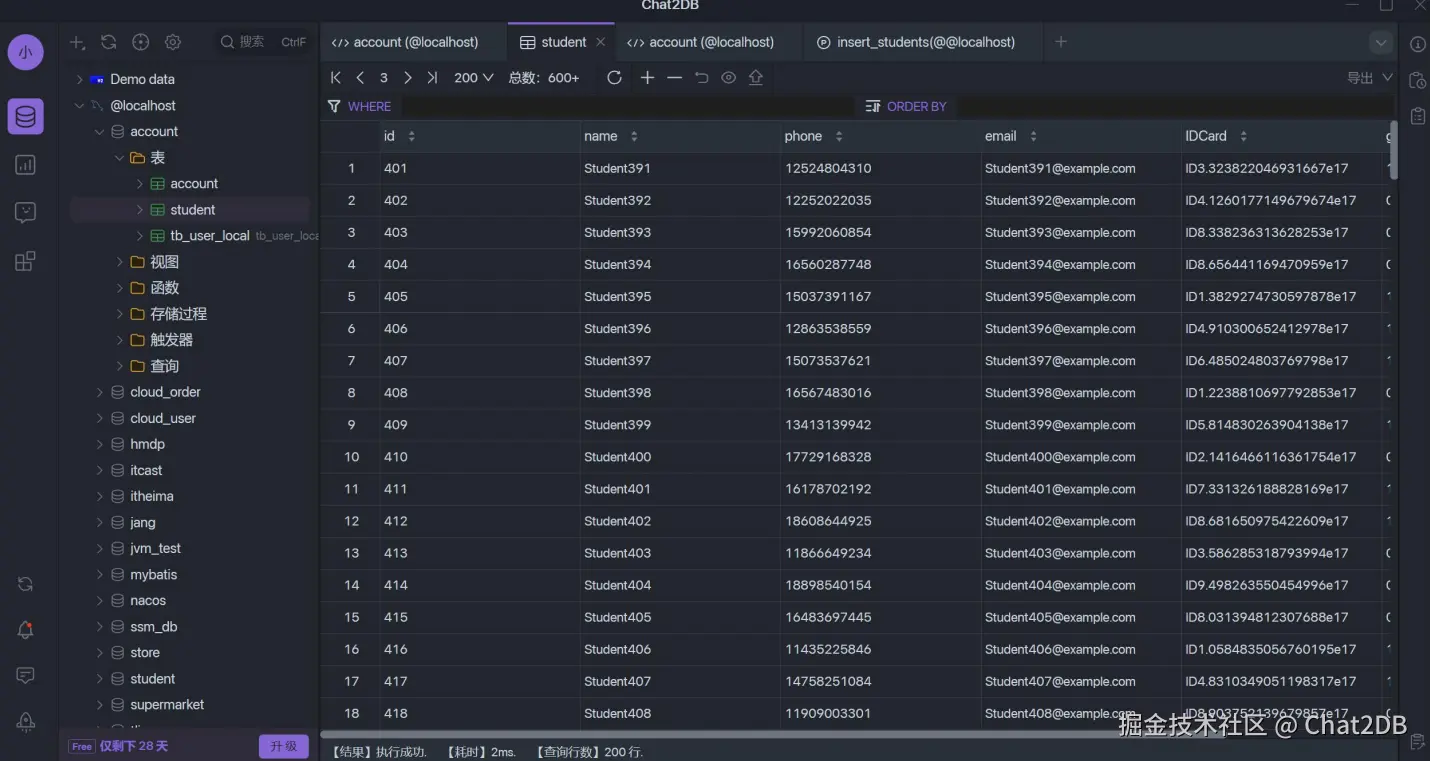
插入数据后的 student 表如下:
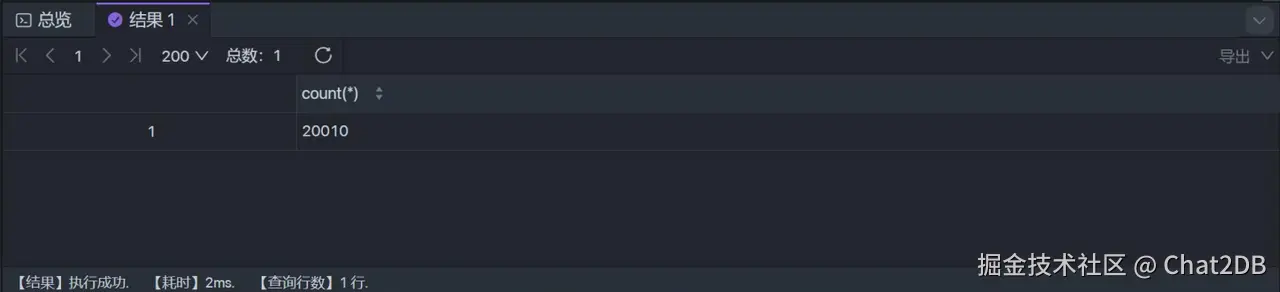
这个时候执行 select count(*) from student 和 select count(1) from student 可以看到解释器的结果如下,耗时均为 2 ms(两者一致,所以就只截了一张图),两者都用主键索引进行行数的统计:
第二步:执行计数查询
创建二级索引 IDCard 进行统计结果如下:

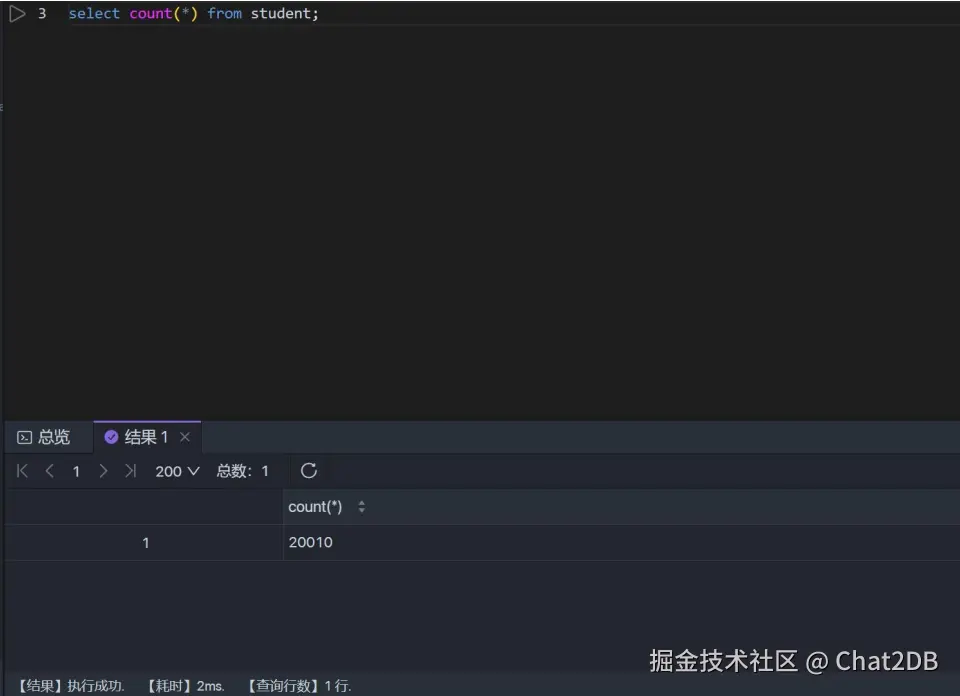
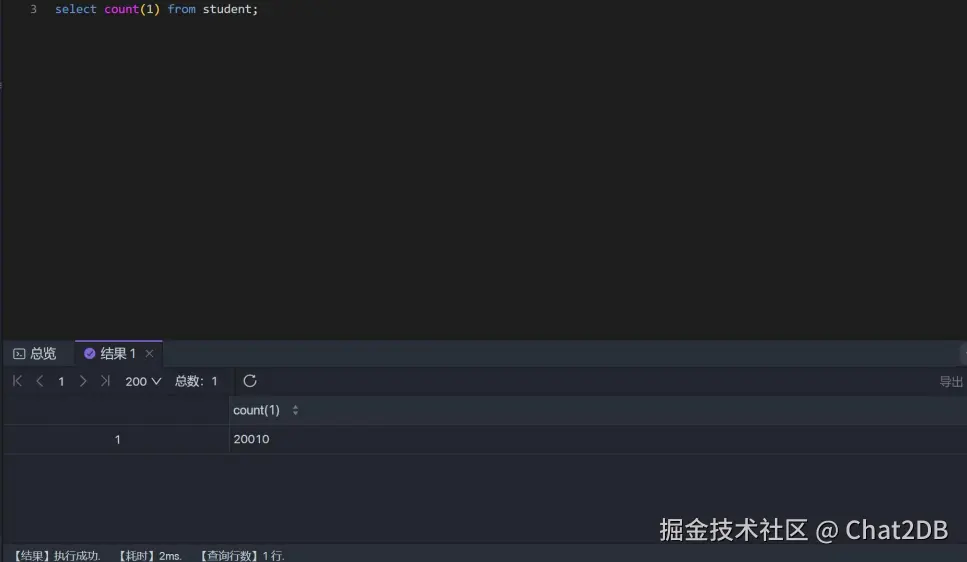
可以看出用二级索引进行统计的解释器结果还是一致。
结论
综上所述,count(1) 和 count(*) 的性能基本相同,并不存在 COUNT(1) 比 COUNT(*) 更快的说法。总体而言,在大多数情况下,两者之间的性能差异是可以忽略不计的。
在选择使用哪种方式时,应当优先考虑代码的可读性和可维护性。count(*) 在语义上更为明确,表示计算所有行的数量,而不依赖于任何特定的值。因此,从代码清晰度的角度出发,通常建议优先使用 count(*)。
当然,如果在特定的数据库环境中,经过实际测试发现 count(1) 具有明显的性能优势,那么也可以选择使用 count(1)。但在一般情况下,不必过分纠结于这两种计数方式之间的性能差异。
希望本文能帮助你在使用计数操作时作出更为合理的选择。
 :count(1) 和 count(*)哪个性能更好?
:count(1) 和 count(*)哪个性能更好?






 400 186 1886
400 186 1886


