一个免费开源可完全离线的OCR工具Umi-OCR(本文附带封装教程DEMO源码)
|
admin 2024年7月24日 15:39
本文热度 907
2024年7月24日 15:39
本文热度 907
|
在《Easy-OCR》一文中,我们详细描述了OCR的应用场景和Easy-OCR的使用,后续有同学反馈,Easy-OCR的安装相对较为麻烦,还需要下载模型包,在使用上也以Python命令为主,对新手同事不是太友好。也有同学反馈为什么不用飞浆Paddle,本质上paddle场景主要面向视觉分析,深度学习场景,而且在安装使用上的难度也不是太低。
所以,今天给大家介绍的是一个不同于Easy-OCR和飞浆Paddle,而是一个无论在部署安装,还是使用上更加简单的OCR软件-Umi-OCR。为了说明这几个OCR区别,整理了一份对比表如下:
| 对比项 | Umi-OCR | Easy-OCR | PaddleOCR |
| 设备要求 | 主要Windows操作系统,Linux(测试中) | 支持多种操作系统 | 支持多种操作系统 |
| 定位 | OCR设别软件,底层依赖OCR识别引擎 | OCR识别引擎 | OCR识别引擎 |
| 易用性 | 图形化界面,适合非专业用户,也提供命令行和API接口 | 适合具有一定编程基础的开发者使用 | 适合具有一定编程基础的开发者使用 |
| 性能 | 性能优化好,底层可采用Paddle引擎,电脑性能足够情况下速度快 | 效率一般,但是可利用GPU加速 | 性能优化好,支持多种硬件加速 |
| 学习难度 | 较低,图形化界面易于上手 | 中等,需要编程基础,但API接口简洁 | 中等,需要编程基础,对比其他Python库可能存在学习曲线 |
| 安装部署 | 无需安装,下载解压即可使用 | 通过pip安装,可能需要下载预训练模型 | 通过pip安装PaddlePaddle,再安装PaddleOCR或使用PaddleHub集成 |
| 多语言 | 支持 | 支持 | 支持 |
| 应用场景 | 截图OCR、批量OCR、二维码识别等 | 文档数字化、名片信息提取、车牌识别等 | 图像识别、自然语言处理、推荐系统等 |
| 批量处理 | 支持批量导入图片进行文字识别,支持多种输出格式 | 支持批量处理,具体实现需结合API使用 | 支持批量预测,可通过编程实现复杂批处理 |
| 离线使用 | 是,完全离线使用 | 是,但需预先下载模型文件 | 是,支持离线 |
一个开源、免费的离线OCR软件。简单、易用,开放API。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。
🏠 项目信息
#Github地址https://github.com/hiroi-sora/Umi-OCR
🚀功能特性
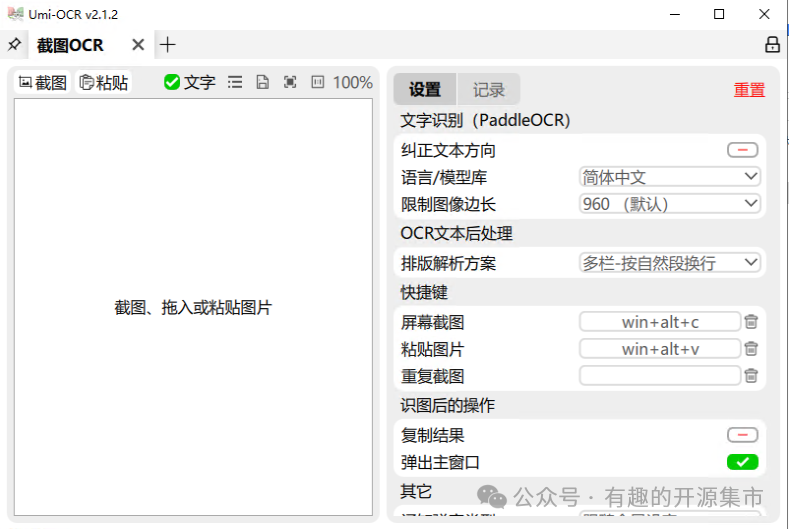
Umi-OCR提供了多种下载方式,可以安装网络环境自行选择。下载后,直接解压使用即可:
# 蓝奏云 (国内推荐,免注册/无限速)https://hiroi-sora.lanzoul.com/s/umi-ocr# Github releasehttps://github.com/hiroi-sora/Umi-OCR/releases/latest# Source Forgehttps://sourceforge.net/projects/umi-ocr
支持屏幕截图,粘贴图片,快捷转文字,支持识别栏编辑文字,允许划选多个记录复制。
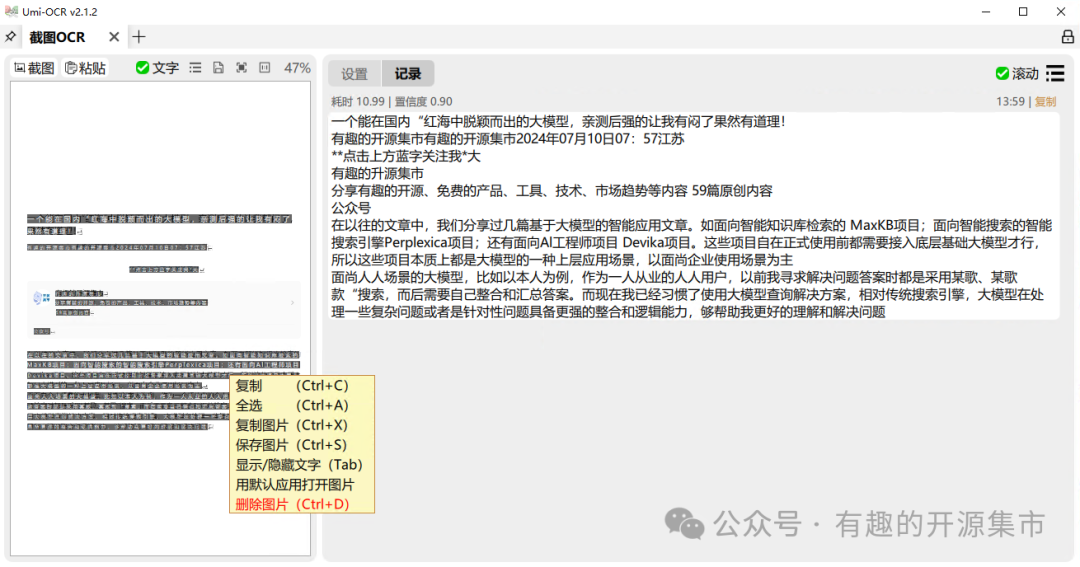
支持设别后文本后处理,整理OCR结果的排版和顺序,使文本更适合阅读和使用。
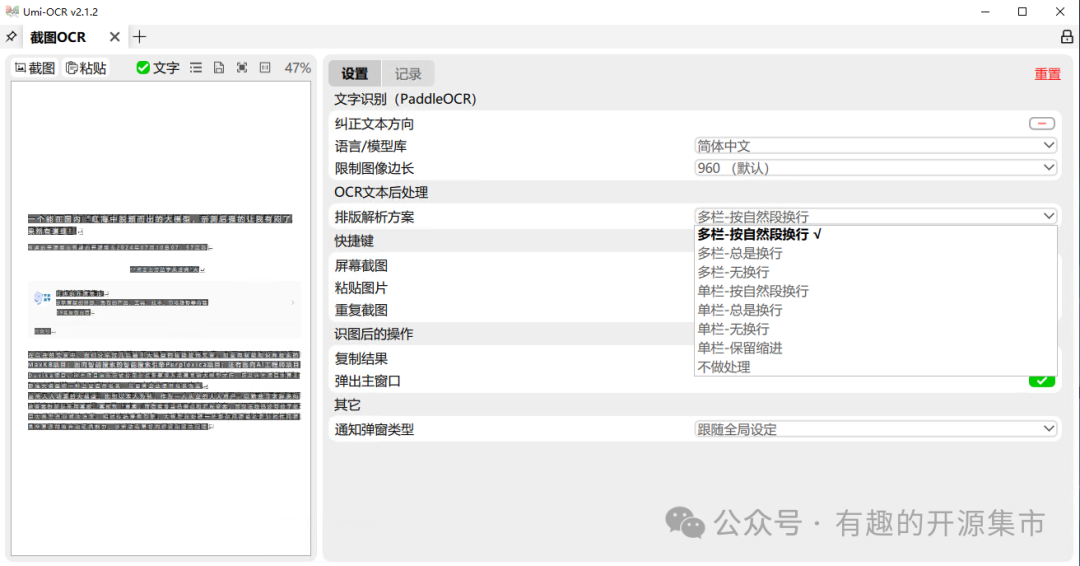
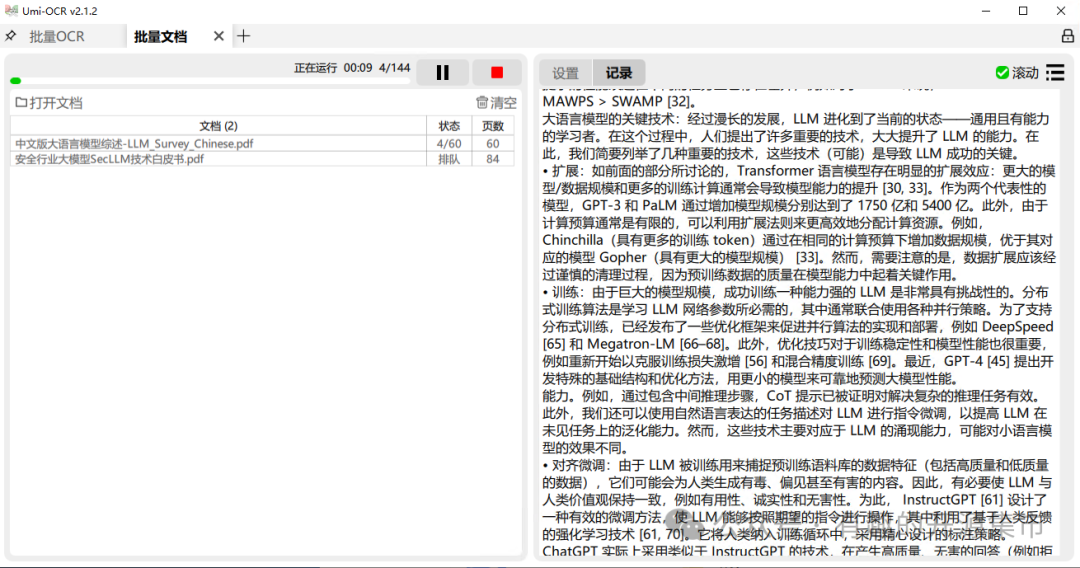
对批量导入本地图片进行识别,支持与截图OCR一样的文本后处理功能,可一次性导入几百张图片进行任务。
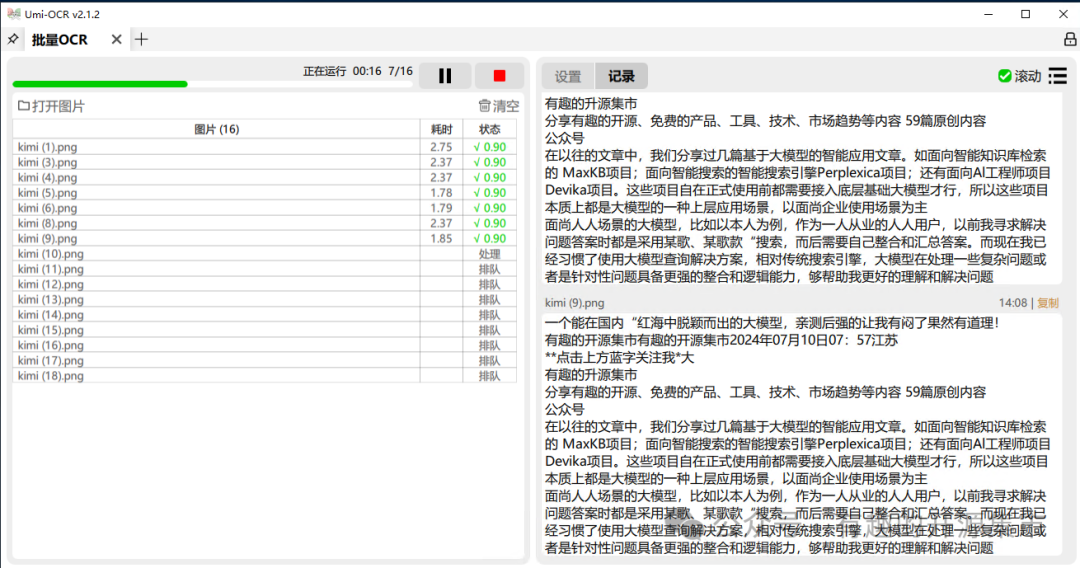
OCR文本后处理支持忽略区域,适用于排除图片中的不想要的文字。
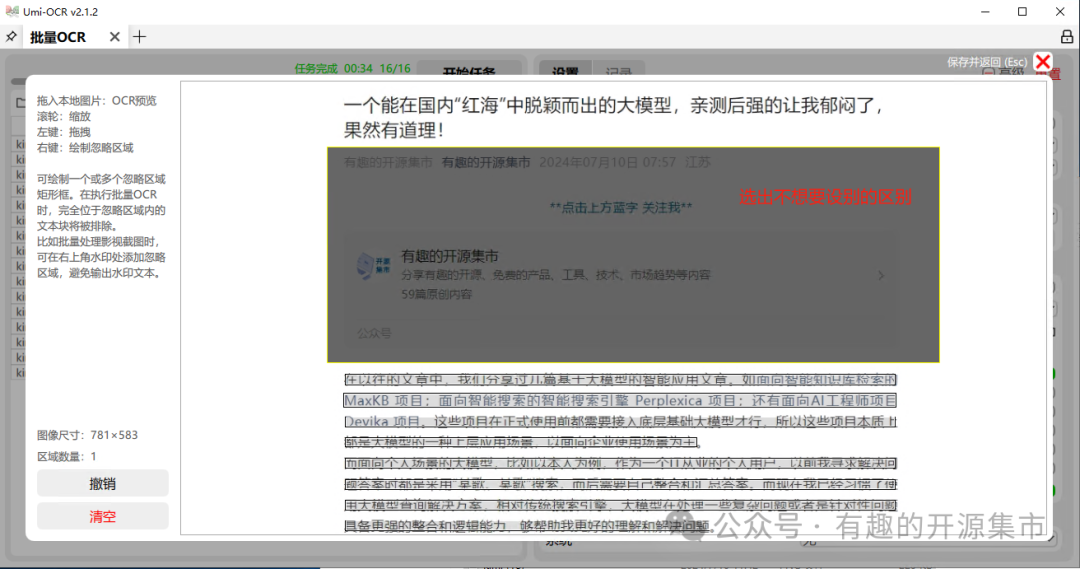
支持pdf, xps, epub, mobi, fb2, cbz 等格式文档批量识别,支持设定忽略区域,可用于排除页眉页脚的文字。
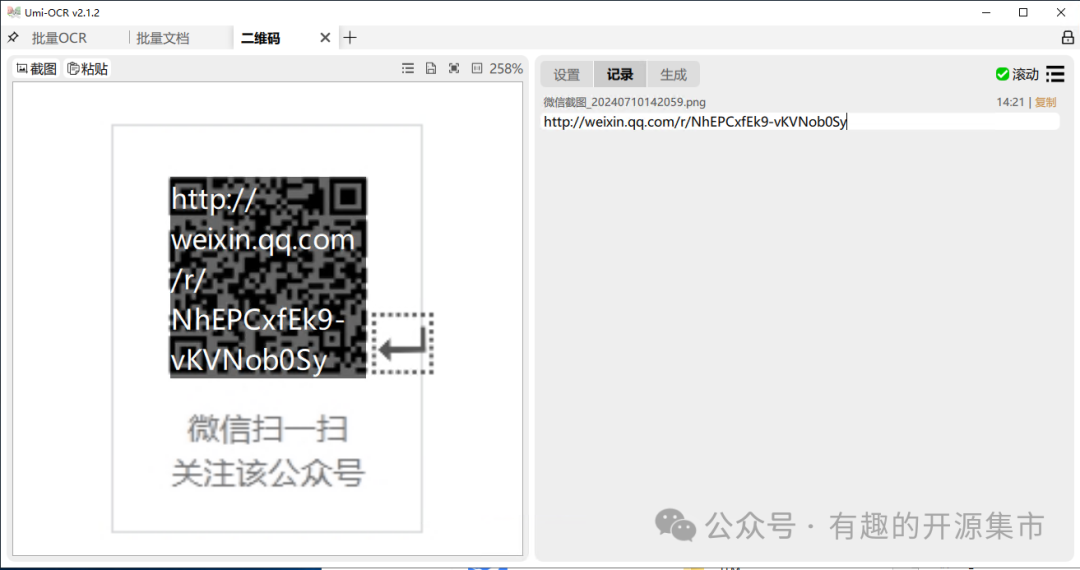
截图/粘贴/拖入本地图片,读取其中的二维码、条形码,支持19种协议。
Umi-OCR同时提供了本地命令行和HTTP接口。本次我们主要基于的Umi-OCR接口,将其封装为一个简单的B/S架构WEB应用。
# Umi-OCR http接口说明文档https://github.com/hiroi-sora/Umi-OCR/blob/main/docs/http/README.md
一、开放HTTP接口地址
在全局设置页中勾选高级设置,允许HTTP服务才能使用HTTP接口,将主机切换到任何可用地址。
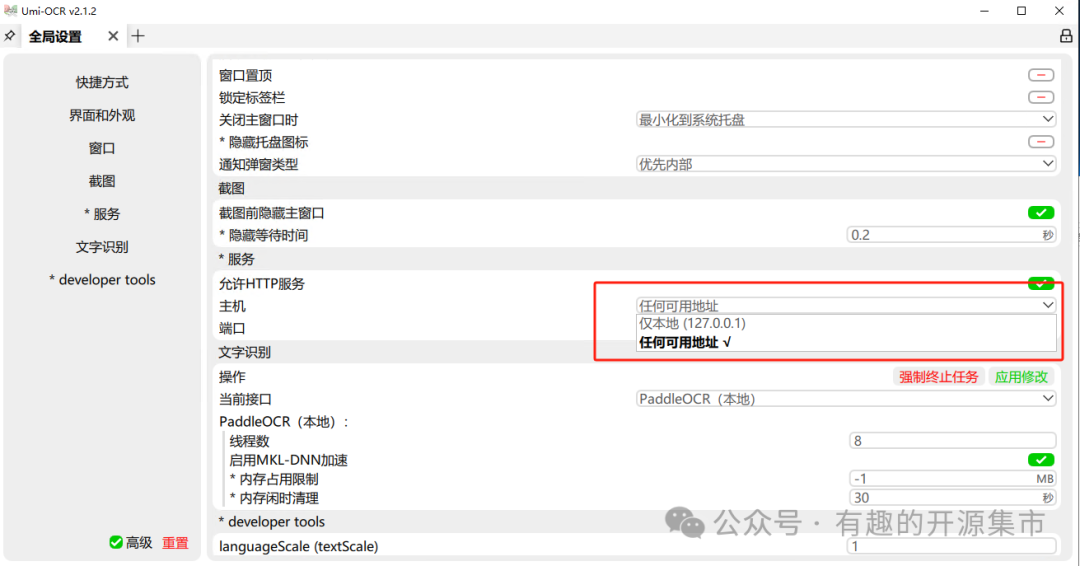
二、WEB封装设计说明
三、具体代码实现
from flask import Flask, request, render_template, jsonifyimport requestsimport base64import osfrom werkzeug.utils import secure_filenameimport json
app = Flask(__name__)app.config['UPLOAD_FOLDER'] = 'uploads/' # 确保这个文件夹存在
def format_result(data): formatted_results = [] for item in data: result = { 'text': item.get('text', ''), 'score': item.get('score', 0), 'bounding_box': item.get('box', []) } formatted_results.append(result) return formatted_results
@app.route('/', methods=['GET'])def index(): return render_template('index.html')
@app.route('/upload', methods=['POST'])def upload_file(): if request.method == 'POST': # 获取上传的图片 image_file = request.files['image'] if image_file: filename = secure_filename(image_file.filename) image_file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename)) # 读取图片内容并转换为base64编码 with open(os.path.join(app.config['UPLOAD_FOLDER'], filename), "rb") as image_file: encoded_image = base64.b64encode(image_file.read()).decode('utf-8') # 调用OCR接口 response = requests.post('http://xxx.xxx.xxx.xxx:1224/api/ocr', json={'base64': encoded_image}) # URL换成运行umi-ocr的服务器地址,解析响应 if response.status_code == 200: result = response.json() result['data'] = format_result(result['data']) # 格式化数据 return jsonify(result) else: return jsonify({'error': 'Failed to connect to OCR service'}) return jsonify({'error': 'No image provided'})
if __name__ == '__main__': app.run(debug=True, host='0.0.0.0')
<!DOCTYPE html><html lang="zh-CN"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>OCR识别结果展示</title> <!-- 引入Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.5.2/css/bootstrap.min.css"> <style> #results { margin-top: 20px; } .result-text { font-size: 16px; color: #333; }</style></head><body> <div class="container mt-4"> <h2>OCR识别结果</h2> <form id="uploadForm" method="post" enctype="multipart/form-data"> <div class="form-group"> <input type="file" class="form-control" name="image" required> </div> <button type="submit" class="btn btn-primary">上传图片</button> </form> <div id="results" class="result-text"></div> </div>
<!-- 引入jQuery和Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.5.1.min.js"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.5.2/js/bootstrap.min.js"></script> <script> $(document).ready(function() { $('#uploadForm').submit(function(e) { e.preventDefault(); var formData = new FormData(this);
$.ajax({ url: '/upload', type: 'post', data: formData, contentType: false, processData: false, success: function(data) { if (data.error) { $('#results').text(data.error); } else if (data.code === 100) { // 将所有文本结果拼接并显示 var allText = data.data.map(function(item) { return item.text; }).join('\n'); $('#results').text(allText); } else { $('#results').text('识别失败或未检测到文本。'); } }, error: function(xhr, status, error) { $('#results').text('请求出错:' + error); } }); }); });</script></body></html>
#需要python3环境,确保环境中安装了Flaskpip install Flask easyocr -i https://mirrors.aliyun.com/pypi/simple/
# 创建运行目录mkdir -p /opt/Umi-OCR/uploadsmkdir -p /opt/Umi-OCR/templates# 将umi-ocr.py文件复制至 Umi-OCR目录mv umi-ocr.py /opt/Umi-OCR/# 将index.html文件复制至Umi-OCR/templates目录mv index.html /opt/Umi-OCR/templates# 运行程序python umi-ocr.py
* Running on http://xxx.xxx.xxx.xxx:5000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 379-609-535

四、使用测试
在页面上传图片,查看识别效果
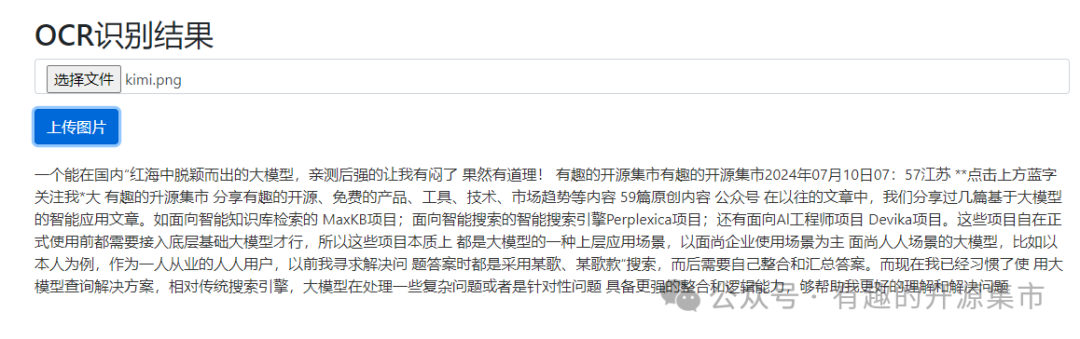
当然,上述只是一个简单的教程,感兴趣的同学可以在DEMO之上扩展批量识别等功能。虽然Umi-OCR在使用上主要面向非专业用户,但是在设计上提供了详细的API接口和命令行。方便专业的开发人员可以按照需要的场景和应用自行扩展和集成。
该文章在 2024/7/24 15:49:36 编辑过






 400 186 1886
400 186 1886

