SQLServer中处理亿万级别的数据
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
先说结论: 在SQLServer中处理亿万级别的数据(历史数据),可以按以下方面进行: 1、去掉表的所有索引 2、用SqlBulkCopy进行插入 3、分表或者分区,减少每个表的数据总量 4、在某个表完全写完之后再建立索引 5、正确的指定索引字段 6、把需要用到的字段放到包含索引中(在返回的索引中就包含了一切) 7、查询的时候只返回所需的字段 首先声明,我只是个程序员,不是专业的DBA,以下这篇文章是从一个问题的解决过程去写的,而不是一开始就给大家一个正确的结果,如果文中有不对的地方,请各位数据库大牛给予指正,以便我能够更好的处理此次业务。 项目背景这是给某数据中心做的一个项目,项目难度之大令人发指,这个项目真正的让我感觉到了,商场如战场,而我只是其中的一个小兵,太多的战术,太多的高层之间的较量,太多的内幕了。具体这个项目的情况,我有空再写相关的博文出来。 这个项目是要求做环境监控,我们暂且把受监控的设备称为采集设备,采集设备的属性称为监控指标。项目要求:系统支持不少于10w个监控指标,每个监控指标的数据更新不大于20秒,存储延迟不超过120秒。那么,我们可以通过简单的计算得出较理想的状态——要存储的数据为:每分钟30w,每个小时1800w,也就是每天4亿3千两百万。而实际,数据量会比这个大5%左右。(实际上大部分是信息垃圾,可以通过数据压缩进行处理的,但是别人就是要搞你,能咋办) 上面是项目要求的指标,我想很多有不少大数据处理经验的同学都会呲之以鼻,就这么点?嗯,我也看了很多大数据处理的东西,但是之前没处理过,看别人是头头是道,什么分布式,什么读写分离,看起来确实很容易解决。但是,问题没这么简单,上面我说了,这是一个非常恶劣的项目,是一个行业恶性竞争典型的项目。
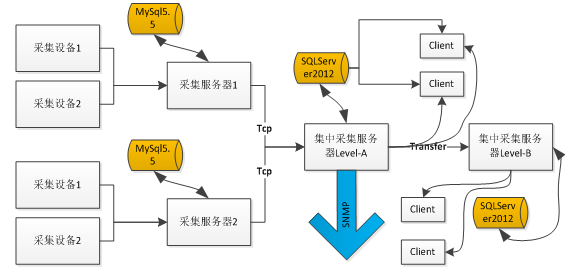
写入瓶颈首先遇到的第一个拦路虎就是,我们发现现有的程序下,SQLServer根本处理不了这么多的数据量,具体情况是怎样的呢? 我们的存储结构一般为了存储大量的历史数据,我们都会进行一个物理的分表,否则每天上百万条的记录,一年下来就是几亿条。因此,原来我们的表结构是这样的: CREATE TABLE [dbo].[His20140822](
[No] [bigint] IDENTITY(1,1) NOT NULL, [Dtime] [datetime] NOT NULL, [MgrObjId] [varchar](36) NOT NULL, [Id] [varchar](50) NOT NULL, [Value] [varchar](50) NOT NULL,
CONSTRAINT [PK_His20140822] PRIMARY KEY CLUSTERED
(
[No] ASC
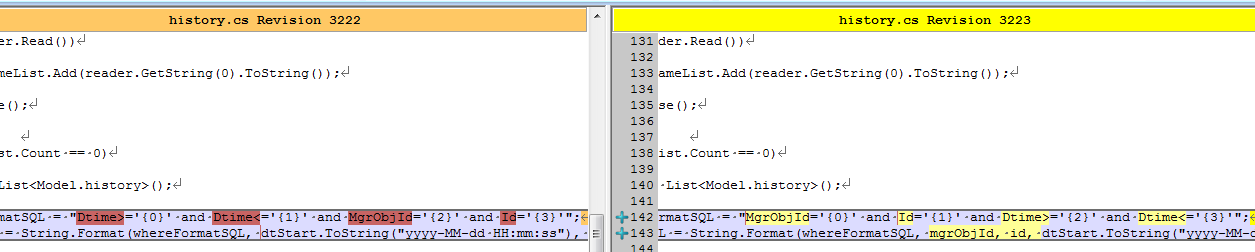
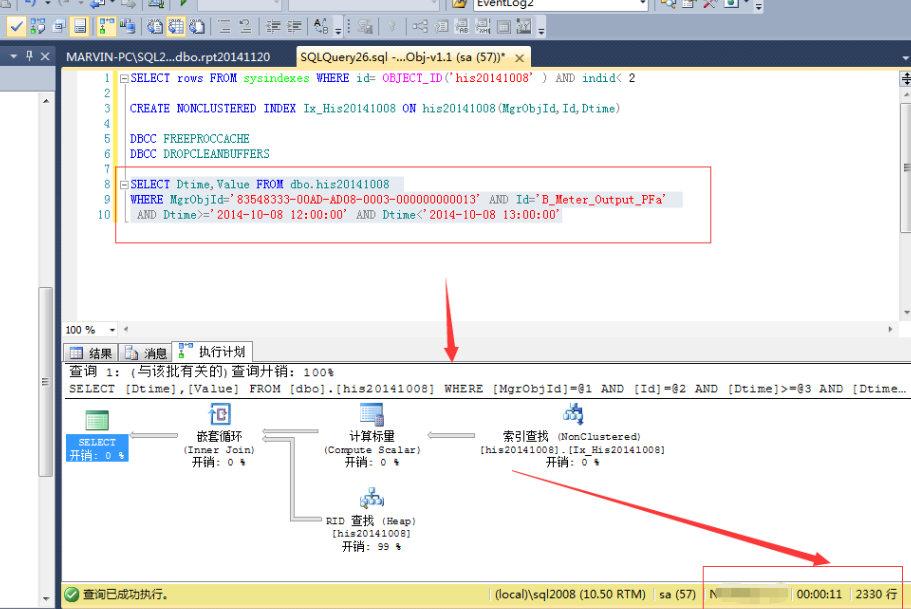
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]) ON [PRIMARY] No作为唯一的标识、采集设备Id(Guid)、监控指标Id(varchar(50))、记录时间、记录值。并以采集设备Id和监控指标Id作为索引,以便快速查找。 批量写入写入当时是用BulKCopy,没错,就是它,号称写入百万条记录都是秒级的 public static int BatchInert(string connectionString, string desTable, DataTable dt, int batchSize = 500) { using (var sbc = new SqlBulkCopy(connectionString, SqlBulkCopyOptions.UseInternalTransaction) { BulkCopyTimeout = 300, NotifyAfter = dt.Rows.Count, BatchSize = batchSize, DestinationTableName = desTable }) { foreach (DataColumn column in dt.Columns) sbc.ColumnMappings.Add(column.ColumnName, column.ColumnName); sbc.WriteToServer(dt); } return dt.Rows.Count; } 存在什么问题?上面的架构,在每天4千万的数据都是OK的。但是,调整为上述背景下的配置时,集中监控程序就内存溢出了,分析得知,接收的太多数据,放在了内存中,但是没有来得及写入到数据库中,最终导致了生成的数据大于消费的数据,导致内存溢出,程序无法工作。 瓶颈到底在哪里?是因为RAID磁盘的问题?是数据结构的问题?是硬件的问题?是SQLServer版本的问题?是没有分区表的问题?还是程序的问题? 当时时间只有一个星期,一个星期搞不好,项目监管就要我们滚蛋了,于是,有了连续工作48小时的壮举,有了到处打电话求人的抓鸡…… 但是,这个时候需要的是冷静,再冷静……SQLServer版本?硬件?目前都不大可能换的。RAID磁盘阵列,应该不是。那么到底是什么,真TM的冷静不下来。 大家可能体会不到现场那种紧张的气氛,其实过了这么久,我自己也都很难再回到那种情境。但是可以这么说,或许我们现在有了各种方法,或者处于局外人我们有更多思考,但是当一个项目压迫你快到放弃的时候,你那时的想法、考虑在现场环境因素的制约下,都可能出现重大的偏差。有可能让你快速的思考,也有可能思维停滞。有些同事在这种高压的环境下,甚至出现了更多的低级错误,思维已经完全乱了,效率更低了……36小时没有合眼,或者只在工地上(下雨天到处都是泥巴,干了的话到时都是泥灰)眯两三个小时,然后继续干,连续这么一个星期!或者还要继续! 很多人给了很多想法,但是好像有用,又好像没用。等等,为什么是“好像有用,又好像没用”?我隐隐约约中,好像抓住了一丝方向,到底是什么?对了,验证,我们现在是跑在现场环境下,之前没有问题,不代表现在的压力下没有问题,要在一个大型系统中分析这么个小功能,影响太大了,我们应该分解它。是的,是“单元测试”,就是单个方法的测试,我们需要验证每个函数,每个独立的步骤到底耗时在哪里? 逐步测试验证系统瓶颈修改BulkCopy的参数 按采集设备存储 于是有了这种结构: 结果验证,比上面的稍微好点,但是不是太明显。 数据表分区??? 停止其他程序 难道是SQLServer的瓶颈? 等等,好像还有个东西,索引,对索引!索引的存在会影响插入、更新。 去掉索引是的,去掉索引之后查询肯定慢,但是我必须先验证去掉索引是否会加快写入。如果果断把MgrObjId和Id两个字段的索引去掉。 运行,奇迹出现了,每次写入10w条记录,在7~9秒内完全可以写入,这样就达到了系统的要求。 查询怎么解决?一个表一天要4亿多的记录,这是不可能查询的,在没有索引的情况下。怎么办!?我又想到了我们的老办法,物理分表。是的,原来我们按天分表,那么我们现在按小时分表。那么24个表,每个表只需存储1800w条记录左右。 然后查询,一个属性在一个小时或者几个小时的历史记录。结果是:慢!慢!!慢!!!去掉索引的情况下查询1000多万的记录根本是不可想象的。还能怎么办? 继续分表,我想到了,我们还可以按底层的采集器继续分表,因为采集设备在不同的采集器中是不同的,那么我们查询历史曲线时,只有查单个指标的历史曲线,那么这样就可以分散在不同的表中了。 说干就干,结果,通过按10个采集嵌入式并按24小时分表,每天生成240张表(历史表名类似这样:His_001_2014112615),终于把一天写入4亿多条记录并支持简单的查询这个问题给解决掉了!!! 查询优化在上述问题解决之后,这个项目的难点已经解决了一半,项目监管也不好意思过来找茬,不知道是出于什么样的战术安排吧。 过了很长一段时间,到现在快年底了,问题又来了,就是要拖死你让你在年底不能验收其他项目。 这次要求是这样的:因为上述是模拟10w个监控指标,而现在实际上线了,却只有5w个左右的设备。那么这个明显是不能达到标书要求的,不能验收。那么怎么办呢?这些聪明的人就想,既然监控指标减半,那么我们把时间也减半,不就达到了吗:就是说按现在5w的设备,那你要10s之内入库存储。我勒个去啊,按你这个逻辑,我们如果只有500个监控指标,岂不是要在0.1秒内入库?你不考虑下那些受监控设备的感想吗? 但是别人要玩你,你能怎么办?接招呗。结果把时间降到10秒之后,问题来了,大家仔细分析上面逻辑可以知道,分表是按采集器分的,现在采集器减少,但是数量增加了,发生什么事情呢,写入可以支持,但是,每张表的记录接近了400w,有些采集设备监控指标多的,要接近600w,怎么破? 于是技术相关人员开会讨论相关的举措。 在不加索引的情况下怎么优化查询?有同事提出了,where子句的顺序,会影响查询的结果,因为按你刷选之后的结果再处理,可以先刷选出一部分数据,然后继续进行下一个条件的过滤。听起来好像很有道理,但是SQLServer查询分析器不会自动优化吗?原谅我是个小白,我也是感觉而已,感觉应该跟VS的编译器一样,应该会自动优化吧。 具体怎样,还是要用事实来说话: 结果同事修改了客户端之后,测试反馈,有较大的改善。我查看了代码:
难道真的有这么大的影响?等等,是不是忘记清空缓存,造成了假象? 于是让同事执行下述语句以便得出更多的信息: --优化之前DBCC FREEPROCCACHE
DBCC DROPCLEANBUFFERSSET STATISTICS IO ONselect Dtime,Value from dbo.his20140825 WHERE Dtime>='' AND Dtime<='' AND MgrObjId='' AND Id=''SET STATISTICS IO OFF--优化之后DBCC FREEPROCCACHE
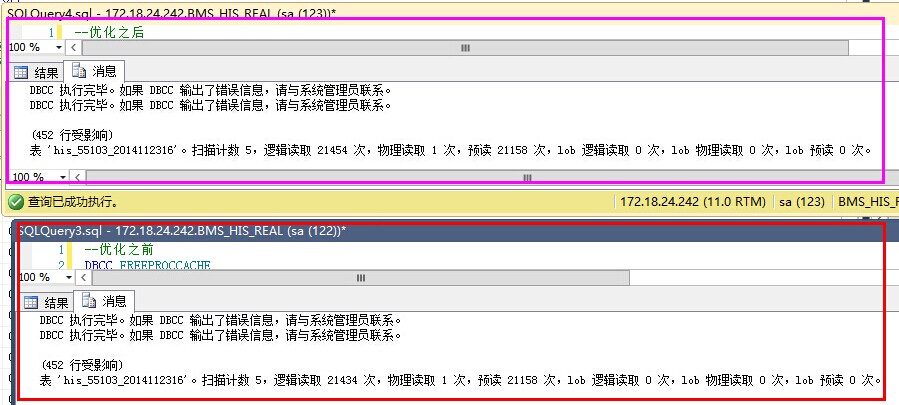
DBCC DROPCLEANBUFFERSSET STATISTICS IO ONselect Dtime,Value from dbo.his20140825 WHERE MgrObjId='' AND Id='' AND Dtime>='' AND Dtime<=''SET STATISTICS IO OFF 结果如下:
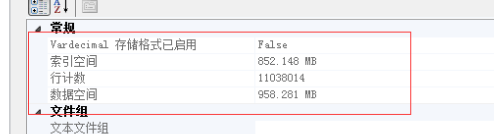
优化之前反而更好了? 仔细查看IO数据,发现,预读是一样的,就是说我们要查询的数据记录都是一致的,物理读、表扫描也是一直的。而逻辑读取稍有区别,应该是缓存命中数导致的。也就是说,在不建立索引的情况下,where子句的条件顺序,对查询结果优化作用不明显。 那么,就只能通过索引的办法了。 建立索引的尝试建立索引不是简单的事情,是需要了解一些基本的知识的,在这个过程中,我走了不少弯路,最终才把索引建立起来。 下面的实验基于以下记录总数做的验证:
按单个字段建立索引 这个想法,主要是受我建立数据结构影响的,我内存中的数据结构为:
先按MgrObjId建立索引,索引大小为550M,耗时5分25秒。结果,如上图的预估计划一样,根本没有起作用,反而更慢了。 按多个条件建立索引 OK,既然上面的不行,那么我们按多个条件建立索引又如何? 结果,查询速度确实提高了一倍:
等等,难道这就是索引的好处?花费7分25秒,用1.1G的空间换取来的就是这些?肯定是有什么地方不对了,于是开始翻查资料,查看一些相关书籍,最终,有了较大的进展。 正确的建立索引首先,我们需要明白几个索引的要点:
跟上述几点原则,我们建立以下的索引: 耗费时间为:6分多钟,索引大小为903M。 我们看看预估计划:
可以看到,这里完全使用了索引,没有额外的消耗。而实际执行的结果,1秒都不到,竟然不用一秒就在1100w的记录中把结果筛选了出来!!帅呆了!! 怎么应用索引?既然写入完成了、读取完成了,怎么结合呢?我们可以把一个小时之前的数据建立索引,当前一个小时的数据就不建立索引。也就是,不要再创建表的时候建立索引!! 还能怎么优化可以尝试读写分离,写两个库,一个是实时库,一个是只读库。一个小时内的数据查询实时库,一个小时之前的数据查询只读库;只读库定时存储,然后建立索引;超过一个星期的数据,进行分析处理再存储。这样,无论查询什么时间段的数据,都能够正确处理了——一个小时之内的查询实时库,一个小时到一个星期内的查询只读库,一个星期之前的查询报表库。 如果不需要物理分表,则在只读库中,定时重建索引即可。 总结如何在SQLServer中处理亿万级别的数据(历史数据),可以按以下方面进行:
转自:http://www.cnblogs.com/marvin/p/4123745.html 该文章在 2024/6/6 9:52:49 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886