大模型的无限上下文与数据集组合艺术
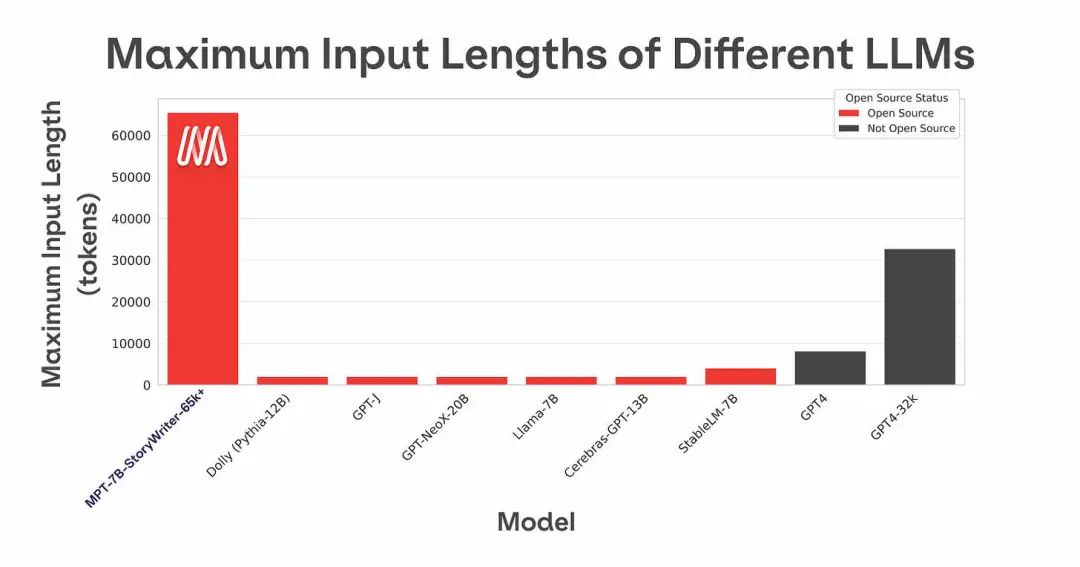
来源 | Latent Space OneFlow编译 翻译|贾川、杨婷、宛子琳 上下文长度曾是GPT-3的最大限制之一。GPT-3最多只能接收4000个词元(3000词,6页),否则就会报错。因此,为处理长文档和提示(prompt),就需要引入 LangChain 等其他检索技术。不过,MosaicML(已被Databricks以约13亿美元收购)在5月初开源的MPT-7B上下文长度可达84000个词元(63000个词,126页),大大扩展了可处理的文本范围,随后,Anthronpic公司开发的Claude模型的上下文长度扩展到10万个词元。
MPT-7B是从头开始训练的,使用了1万亿个词元的文本和代码作为训练数据。相比其他类似模型(如Pythia和OpenLLaMA使用了3000亿个词元,StableLM使用了8000亿个词元),MPT-7B的训练数据规模更大,其质量可与LLaMA-7B相媲美。该模型在MosaicML平台上进行训练,使用了440个GPU,训练过程耗时9.5天,并且没有人为干预,成本约为20万美元。与其他开放模型不同,MPT-7B开放了商业使用许可,并利用FlashAttention和FasterTransformer对快速训练和推理进行了优化。
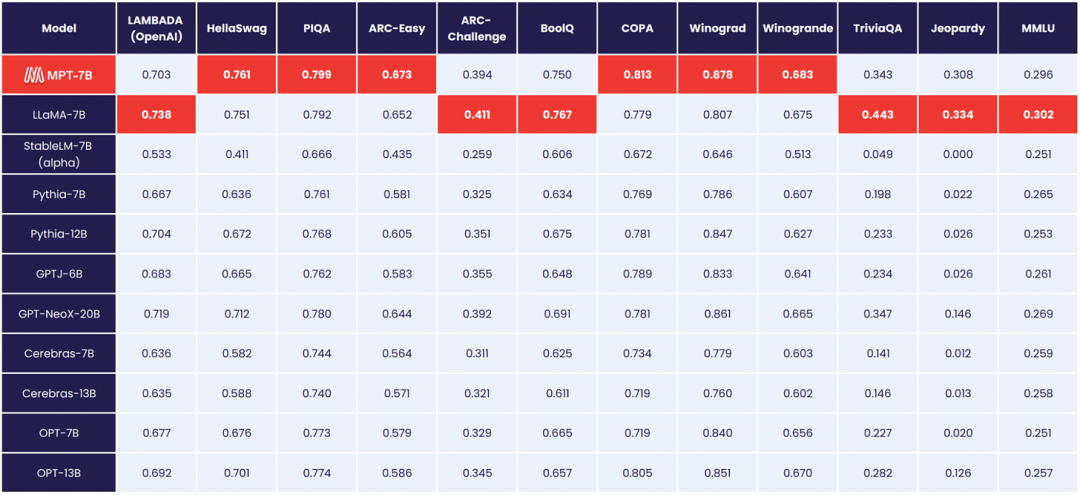
(MPT-7B在零样本学术任务中的表现) MosaicML还发布了三个基于基础MPT-7B进行微调的MPT-7B-Instruct、MPT-7B-Chat、MPT-7B-StoryWriter-65k+模型。
除模型checkpoint外,该团队还通过他们新的MosaicML LLM Foundry开源了用于预训练、微调和评估MPT的完整代码库。以上表格就是利用LLM Foundry中的上下文学习评估框架而创建。 MosaicML首席科学家Jonathan Frankle和研究科学家Abhinav Venigalla是MPT-7B的负责人,主导了MPT-7B的整个训练过程。在Latent Space的最新播客中,主理人Swyx、Decibel Partners合伙人Alessio与他们探讨了MPT-7B训练过程的创新之处,解释为什么LLM数据集组合是重要且神秘的艺术。此外,某些传统的多项选择基准测试对于正在构建的这种技术可能帮助不大,他们也将探讨这背后的原因。 (以下内容经授权后由OneFlow编译发布,转载请联系OneFlow获得授权。来源:https://www.latent.space/p/mosaic-mpt-7b#details) 1 MPT-7B模型的构建 Swyx:你们当时为什么会开发MPT-7B? Abhinav:MPT-7B项目大概花了6-12个月时间。我们从去年夏天开始研究语言模型,并发布了一篇博客,对语言模型进行了分析,发现训练成本实际上可能比人们想象的低得多。也是从那时起,我们受Meta AI发布的LLaMA模型和许多其他开源工作的启发,开始着手创建真正优秀的、拥有70亿参数的模型,这就是MPT的由来。 Alessio:你曾在其中一个播客中说:Mosaic没有构建和发布模型的计划。但最终你们还是发布了模型,是什么让你们改变了主意? Jonathan:我认为,主要有几个因素:我们至今仍然缺乏一个一流模型。与OpenAI不同,我们的业务围绕客户创建自己的模型展开,而我们主要为其提供工具,为了确保这些工具的有效性,我们就必须先创建自己的模型。 必须清楚一点,如果客户能做出伟大的事,那么我们也同样能实现伟大的成就。Twitter上有很多人向我提出质疑,怀疑Mosaic所展示数字的真实性,比如Ross Whiteman就曾提出“让我们看看实际的成果”,对此,我想说的是,“Ross,你认为这些成果如何?”我们在9.5天的时间里以20万美元的成本研发了模型,所以你们也可以做到。 Swyx:参考你们去年发布的数据,最初估计训练GPT-3的成本不到45万美元,后来降至10万美元;Stable Diffusion的成本也由16万美元降至不到5万美元。 Jonathan:对于10万美元这个数字我还是很谨慎的。虽然还未实现这一目标,但我们会朝着这个方向前进,这也是给Abhi的一大挑战。 Swyx:MPT-7B模型有三个变体,其中一个在上下文长度方面达到SOTA,这些模型的训练过程是怎样的? Abhinav:我们的基础模型是对LLaMA-7B的再创造,拥有70亿参数,训练数据达1万亿个词元,为微调模型提供一个高效、不需要过多干预的训练起点。微调模型也非常有趣,比如MPT-7B-StoryWriter-65k+可用于故事编写,上下文窗口长度为65,000,还可以根据已知内容进行续写。 当然,这只是我们想到的方向之一,你可以利用MPT-7B Base模型来构建自定义模型,以适用不同的需求,如长上下文代码模型或特定语言模型。所以基于基础模型构建了三个变体,MPT-7B-Instruct、MPT-7B-Chat和MPT-7B-StoryWriter-65k+,分别用于遵循简短指令、聊天对话和编写故事。 Alessio:在训练模型时,你们是如何决定要选用多少词元和参数的?70亿和30亿模型参数似乎是当前流行的两个神奇数字。 Abhinav:对于训练模型来说,规模定律(scaling law)可以告诉你如何最有效地利用训练计算资源。比如预算为20万美元,那么依照规模定律,就能给出一套最有效的训练方案。 其中,我们最常遵循的是Chinchilla定律。而对于MPT-7B模型及其相关变体,却并未严格遵循这些定律,因为我们想确保模型适用于个人使用并具备良好的推断性能,所以对其进行了过度训练,超过了Chinchilla Point(指以词元衡量的数据级别)。网上有人将这些模型戏称为长蛇狗(Llongboi),因为其训练时间相当长,以7B模型为例,Chinchilla Point可能是1400亿个词元,而我们实际训练了1万亿个词元,因此训练时间几乎是正常情况下的7倍。 Swyx:Llongboi指的是一种训练方法吗? Jonathan:Llongboi只是内行的一句玩笑话,指的是所用词元数量多于Chinchilla定律所规定数量的训练方法。可以看到,Llongboi开头有两个“L”,用于致敬LLaMA。我们的CEO曾在Twitter上将这个名字公之于众,将模型称为“Llongboi”。有时我真的想拿走他的Twitter密码,以免提前泄密,不过现在全世界都已经知道这个名字了。 2 关于架构、ALiBi、上下文 Alessio:Flash Attention和Faster Transformer是你们构建模型的两个核心要素,它们的优势是什么? Abhinav:Flash Attention是Full Attention的更快实现,由斯坦福的Hazy Research实验室开发。去年九月,我们将Flash Attention集成到了我们的库中,它在训练和推理速度方面起到了很大作用。与其他Hugging Face模型相比,这个模型十分特别,它可以在一般的Torch Attention和专为GPU设计的Flash Attention之间进行切换,这让模型的训练速度提升了2倍左右,推理速度提升了50%-100%。 Swyx:是什么促使你们选择了ALiBi位置编码? Abhinav:我们通过一种有趣的方式,将ALiBi位置编码、Flash Attention以及训练稳定性相结合。ALiBi能够消除模型对位置嵌入的需求。之前,如果一个词元的位置是1,那么你需要添加一个特定的位置嵌入,并且无法超过最大位置(通常为2000)。但是通过ALiBi,这个问题就被解决了。我们只需要在Attention Map上添加一个偏置(bias),这就像一个斜坡,如果在推理时需要更长的位置范围,它会将这个斜坡延长到更长的位置数。由于斜坡是连续的,且可以进行解释,所以这种方法是可行的。 有趣的是,通过Flash Attention,模型节省了大量的内存并提升了性能,所以我们在去年就开始对具有非常长上下文(长达65k)的模型进行性能测试,同时,要进行稳定训练也非常难。后来,我们尝试将ALiBi整合进模型,结果模型稳定性获得了显著提升。现在,我们可以在非常长的上下文中稳定地训练故事写作模型,并保证高效地使用它们。 Jonathan:上下文长度在技术上是无限的。只要给予足够的内存,对话可以无限延续下去。我们认为,模型能够处理的最长数字是84K,这是实践中人们能够轻松处理的最长上下文长度。但我们在实践中也尝试过超84K的上下文长度,我们完全可以处理更长的长度。 Swyx:比如我们可以给模型输入小说《了不起的盖茨比》,然后让模型根据输入文本续写小说,最后模型输出了相当精彩的内容。 Jonathan:在Mosaic内部存在许多非常好的故事结尾版本。其中一个版本描述了盖茨比的葬礼,尼克开始与盖茨比的鬼魂交谈,盖茨比的父亲也出现了,然后他和汤姆出现在了警察局。这个版本非常看重情节,描述了接下来会发生什么。此外,许多版本的结尾非常有菲兹杰拉德的风格,它们的文字都十分优美。因此,我们可以看出模型似乎确实在处理输入,并产生了有意义的输出,这一点十分令人激动。我们可以利用这种上下文长度做很多事。 Alessio:记忆开始成为模型的限制条件之一,那么应该如何选择参数大小和上下文长度? Jonathan:最近,关于长上下文的研究引起了大量关注,并出现了一系列相关论文。然而,这些论文并不完全准确,在某种程度上,尤其是注意力机制方面,它们在非二次注意力机制(如近似的、分层的注意力)和明确且正确的二次注意力之间做了权衡或取舍。我很看好近似方法,因此迫不及待地想深入研究这些论文。 通过撰写和阅读论文,我学到了一个重要的教训,即在亲身实践前,不要轻信任何数据。在Mosaic时,我们曾多次在实施中失望过,因为这些论文一开始看起来很有希望,但实现后才意识到,论文对数据做了手脚。因此,我对数据总是持怀疑态度,在重新实施并验证之前,不会轻信任何结果。总的来说,这种实践给予了一定回报,很多时候,这些理论在实践中并不如预期那样有效。 3 MPT-7B的特点 Swyx:MPT-7B有什么具体特点? Abhinav:我会将其分为两部分,首先是训练的稳定性问题。该问题又可分为三部分。首先,模型在训练过程中需要避免损失峰值,这是我们的第一道防线。在我看来,在训练规模为70亿参数时,损失峰值不是一个大问题。然而,随着训练时间延长,避免损失峰值会变得困难。我们花费了很长时间来研究如何调整初始化方法、优化器和架构等,以防止损失峰值的出现。即使在我们的训练过程中,如果仔细观察,还是能发现一些小的间歇性峰值,但这些峰值会在几百个step内恢复正常,这是非常神奇的现象,它能够帮助我们自然从峰值损失中恢复过来。 确定性(determinism)和智能恢复策略是我们的第二道防线。如果发生灾难性错误,我们将能够快速恢复训练,在故障前的几个批次内应用一些干预措施。对于可能出现的问题,我们做了多种准备。但在MPT-7B的训练中,我们完全没有用到这些备用措施,不得不说这是一种幸运。 正确的训练基础设施是第三道防线。如果我们尝试在数百个GPU上对模型进行训练,这时常常出现硬件故障问题。比如在512个GPU的大型集群中训练模型,几乎每隔两天训练就会失败一次,失败原因可能是网络故障等。 一般情况下,人们会设立全天候待命团队来处理这些故障。当出现故障时,团队会尝试检查集群、移除损坏节点、重新启动等,这是一项非常繁琐的任务。我们曾经花了几个月时间来手动检查错误,但现在我们构建了一个平台,以实现模型训练过程中每个节点的自动化处理。 当模型运行出现问题时,我们的自动监控系统会停止作业、测试并检查损坏节点,再重新启动。由于我们的软件具有确定性和快速恢复能力,所以模型可以很好地继续运行。因此,我们在模型日志中有时可以看到,凌晨2点模型出现故障后,它在几分钟内就恢复了正常运行,无需团队成员人工处理。 Jonathan: 要做到这一点确实不容易,几个月前模型如果出现了硬件故障,那么团队成员将不得不在凌晨两点起床,去检查节点故障原因,重新启动作业。之前即使在70亿参数规模的训练中,我们也经常遇到灾难性损失峰值,这些问题严重影响了模型的训练。 现在,我们已经通过逐步改进的方式解决了这些问题。正如Abhinav所说,现在在训练多个模型的同时,我们可以悠闲地坐在办公室,无需担心模型出现问题,从而导致训练中断。 4 数据选择和重复以及LLM的评估挑战 Swyx:数据选择是你们的关注重点,可以展开讲讲吗? Jonathan:在我尝试将所有的GPU用于数据处理而非实际训练模型时,Abhi几乎要杀了我。我们知道,训练模型需要大量的数据,但也存在许多不确定的因素。 一是不同数据来源中哪些种类是重要的,二是重复的重要性。其中,关于重复的问题可以进一步分解为质量和数量的权衡。假设我有世界上最好的100亿个词元数据,那么是将其重复训练一百次更好,还是使用1万亿个低质量、最新的词元数据更好?当然,或许存在折中点,但如何确定高质量数据也是一个问题,目前还没有明确答案。如果现在回到学术界,我一定会为此写一篇论文,因为我对其中的情况还一无所知。 Swyx:至今还没有看到有关这方面的研究论文。 Jonathan:论文研究的中心问题是“应该使用什么样的数据集组合”。 在创建模型的过程中,我回到了曾任教的乔治敦大学法学院,与一群法学院的学生坐在一起讨论。我为他们给出了高质量数据集、数据混合方式,以及拥有的词元数量,然后让他们为自己的模型创建最好的数据集。 他们对LLM一无所知,只知道输入数据会影响行为。我告诉他们要创建一个混合体,以涵盖所有不同的权衡考量。起初可能需要大量英文语料,可通过网络获取;如果想使其变成多语言模型,那么英文语料就会减少很多;另外,是否将代码包含在其中。 有人认为,代码可以使模型在逻辑推理方面表现更好,但我从未见过任何证据支持这一观点。虽然我们确实开发了出色的代码模型,但代码模型能否带来更好的思维链推理能力,这还需要进一步研究。 GPT-3的一个版本据说是从小说《达·芬奇密码》开始训练的,由此有人认为这可能会有用,但并没有证据;也有人认为将精力放在那些优质数据源(如维基百科)上会有助于模型的训练,可也缺乏证据。 因此,我们对多种不同数据混合进行尝试,发现总有一些数据混合比其他的效果更好或更差。比如“The Pile”是一个非常稳定的数据混合,但根据评估指标,还有其他更好的数据混合。下面我还会谈到评估问题,该问题非常重要。 T5模型最初是在C4数据集上训练的,该数据集表现得异常好。当我在Twitter上发布相关信息时,EleutherAI的Stella Beaterman在内的其他人也提到了这一点。在T5模型的原始论文中,对C4数据集的预处理方法看起来很奇怪,作者从数据集中删除了所有包含“JavaScript”一词的内容,因为他们不想出现与JavaScript相关的警告信息。此外,他们还删除了包含大括号的内容,因为他们不想获得包含JavaScript的内容。 他们查看了一份不良词汇列表,并删除了其中包含不良词汇的内容。然而,该不良词汇列表中其实包含了一些实际上并不是不良的词汇,比如“gay”。但由于有这样的清洗过程,得到的数据集似乎变得无与伦比得好。从这一点来看,我们对数据一无所知。 实际上,我们还用到一个名叫MC4的数据集,MC4和C4进行了相同的预处理,只是增加了更多的网页调用(web call),但与C4相比,MC4的英语部分要差很多,原因不得而知。 为此,我设定了两个标准: 首先,英语部分至少要和MC4一样好。相对于其他可用数据集,MC4的英文部分要好一些。其次,全力推动数据多样性,确保数据集包含代码、科学论文和维基百科等内容,因为人们会用该模型完成各种不同的任务。 Swyx:你认为MMLU(Massive Multitask Language Understanding)和BIG-bench等评估方法不够有说服力? Jonathan:这类方法无疑都是做两类任务。一是多项选择式任务,其中包含一个正确答案,这可以让模型生成A、B、C或D等选项,然后通过计算每个可能答案的困惑度(perplexity),选择模型最可能生成的答案。但我们并不要求模型做多项选择题,而是进行第二种开放式生成任务,比如摘要。使用类似于BLEU和ROUGE的指标进行比较不够准确,有许多出色的论文摘要和开放式生成方法。相比之下,人工是一种较为可靠的评估标准,但人工评估非常耗时费力,无法实时地与模型进行比较,或许在以后有可能实现。 Abhinav:我们有一支出色的评估团队,正在帮助我们构建新的指标。 Jonathan:但很难对LLM进行评估,我认为,这些指标中的任何一个都不能真正体现到我们在实践中对模型的期望。 5 模型训练的降本增效 Swyx:现在人们需要花费三到十天的时间去训练模型,你们想将时间缩短至多久? Abhinav:就原始模型训练效率的提升而言,今年可能是最令人兴奋的年份之一。今年软硬件都出现了相应升级,首先是英伟达的新一代硬件H100s,单单这一项就能提升至少两倍的性能。其次还有一种新的浮点数格式FP8,单独使用也能达到同样的性能提升。 几年前,我们开始使用32位精度,之后英伟达推出了16位精度。经过几年的发展,因为要求不断提高,我们逐渐掌握了16位训练技巧。 今年有了FP8,我们能将吞吐量提升两倍,也就是将成本降低两倍。同时,我们已经开始在H100上使用FP8对LLM训练进行性能分析,这方面的进展十分迅速。因此,仅仅通过硬件方面的进步,我们就能大幅降低成本。 此外,还有许多架构应用方面的研究。我们正在探索引入一些稀疏性方法,但并非完全无规则的稀疏性。是否有一种类似门控机制或者MoE风格的架构方式可以实现该目标? 我们最初的目标是将GPT-J模型的训练费用从50万美元降至10万美元 ,如果我们能在年底实现,那将是了不起的成就。 Jonathan:这一想法并非空中楼阁。虽然现在还未达到该阶段,但这一目标很可能2023年就能达成。 有关训练与推理成本的统计数据十分稀缺。Google的David Patterson发表了一篇博文,讨论了Google在机器学习方面的能源使用情况。经过详细分析,在过去三年中,谷歌将五分之三的资源用于推理,五分之二的资源用于训练。以上是Google的数据,他们为数十亿用户提供模型。 谷歌可能是全球推理负载最大的地方。这还只是针对训练的资源分配,推理占五分之三,训练占五分之二。而硬件可能更为昂贵,硬件的网络结构更为复杂,因此可能会是训练和推理对半分的配置。以上是谷歌的分配比例,但对于其他公司来说,训练可能会占更高权重。 6 开放对于AI研究的重要性 Alessio:以前的训练成本十分昂贵,这导致我们无法进行足够多的实验,所以在选择数据集等方面存在很多问题。 Jonathan:研究生期间,我曾对朋友们嫉妒不已,因为他们有GPU,而我的笔记本电脑上没有,所以无法训练任何模型。我曾幻想过能够中彩票,这样我就可以拥有一个K80 GPU了。 在内心深处,我仍然是那个渴望进行科学研究的学生。我坚信,如果我们想要进行科学研究,并真正理解这些系统,了解如何使其良好运行,了解其行为、安全性和可靠性等要素,我们就必须降低训练成本,这样才能真正进行科学研究。以生物试验为例,我们需要进行多个细胞培养和实验才能确保药物有效,在真正了解事物之前,进行大量科学研究必不可少。 Abhinav:MosaicML拥有众多客户,他们都在尝试训练模型,因此公司有动力投入大量资源和时间进行科研。只有真正了解应该如何训练模型,我们才能帮助更多人。因此,对于我们来说,这种聚合过程非常重要。 我记得以前谷歌发表过一篇论文,针对批次大小或其他问题进行了调查。这篇论文可能耗费了数百万美元,它给整个社区带来了巨大好处。现在,我们都能从中学习,节省开支,而无需花费大量资金。因此,对于Mosaic来说,通过试验研究我们在数据、预训练架构等方面具备了深刻的洞察,这也正是客户选择我们的原因。 Jonathan:开放对于AI社区十分重要。从某种意义上说,我们没有封闭的理由,通过帮助客户训练模型来获得收益,对我们来说与社区分享成果没有损失,毕竟最后我们要通过定制模型和优秀的基础设施来赚取收入,并将这些方面整合在一起,这也是我们将公司命名为MosaicML的原因。 我们一直秉持着放开的态度,不会对取得的成果遮遮掩掩。但现在,我发现我们已经成为了行业里最大的开源实验室之一,这是一个很可悲的事实,因为就整个行业而言,MosaicML并不算大,我们只有大约15名研究人员,其他许多实验室都变得封闭,不再公开发表太多内容。但MosaicML将继续保持与社区的交流和分享,尽力成为开放研究的先锋。尽管我们的规模和研究数量无法与大型实验室相媲美,但我们将继续分享所学内容,努力为社区创造资源。 当我与政策制定者讨论AI生态系统时,总会提及一个普遍担忧:缺乏开放性将阻碍创新的步伐。多年来,我始终强调这一问题,但最终还是成为了现实。我提倡开源,但不认为每个人都会分享自己的成果。我们曾一度将开源视为理所当然,但如今这种情况已不复存在。 我认为这将会拖慢我们的发展速度。很多时候,各个实验室都存在某种一元文化,而交流沟通是科学进步的重要动力。因此,开源不仅在开源社区和学术界中不可或缺,其对于技术的进步也至关重要。我们需要一个充满活力的开源研究社区。 7 未来发展趋势 Swyx:你提到很多东西都不会长久存在,很容易被替代,但Transformer会长期存在。 Jonathan:Transformer将会一直存在。卷积神经网络(CNN)至今仍在使用,视觉 Transformer并未取代其地位。再看循环神经网络(RNN),已经存在了几十年,但依然活跃在许多领域。因此,实现基础架构的重大改进十分困难。 Abhinav:我认为,你的赌注很大程度上取决于什么被定义为attention(注意力)。如果替换掉QK矩阵乘法这样的操作,用类似的方法代替,这会对结果产生什么影响呢? Jonathan:说到底,这只是一个全连接的前馈网络,带有简单注意力机制的Transformer。所以情况可能会有所改变,但我们仍像Ashish Vaswani(Transformer作者)六年前设想的那样继续使用Transformer,也许在未来还将继续使用。 Abhinav:我认为它将变得类似于MLP(多层感知机),这是我们目前唯一的选择,因为现在架构已经进行了大量简化,只剩下一些线性层、残差连接、注意力、点乘操作。 Jonathan:你的假设是架构会变得更简单,但现实可能相反,架构也许会变得更加复杂。 Swyx:最近关于“涌现现象”的争论,你们对此有什么看法? Abhinav:我看过类似论文,这些可能只是评估技术的副产品,如对数扩展(log scaling)、评估指标,以及我们正在进行的网格化精度(meshing accuracy),这是一种严格的二元判定,即将结果分为正确或错误,而没有考虑更细致的连续性差异。 但是,与Jonathan关于评估的观点类似,我们在评估指标的多样性方面也存在一个问题:当我们发布这些模型时,即便是聊天模型、指令模型,人们也常将其用于各种不同任务。我们事先几乎无法精确地测量和评估各个维度,即使规模达到70亿,这些模型在一些十分困难的MMLU任务上仍然表现欠佳。有时它们的得分几乎只略高于随机机会,尤其是处理十分困难的任务。 因此,随着我们追求更高质量的模型,其中一些问题可能对我们更有用。但是,我们在开发MPT-7B时有点盲目,因为并不完全了解模型的最终表现。只能根据一小部分常见的感知推理任务来进行开发,并且通过将这些指标与其他开源模型进行比较来评估性能。 Alessio:我认为,快速推理和训练是目标之一,因此需要在解决最困难的任务和快速处理其他任务之间做出权衡。 Abhinav:是的。即便是70亿数据规模,人们也会尝试在家中的CPU上运行,或者尝试移植到他们的手机上,主要是因为小规模应用会促使人们采用这项技术,而且这是当下的一个重要趋势。 Alessio:AI领域有哪些事情的发展速度要比预期快得多? Jonathan:记得GPT-2发布时,我并没有觉得很兴奋,但当时它已经拥有了15亿参数。随着模型规模不断扩张,它们的性能不可能持续提升。然后GPT-3发布了,我也只是认为它在生成文本方面有些许进步,但我一次又一次地错了。通过预测下一个词元,扩大模型规模可以产出十分有用的模型。 公平地说,我们几乎都对此持错误的看法,所以也不能完全归咎于自己。否则,早在我有机会行动之前,谷歌、Facebook和微软研究院就会推出杀手级的语言大模型了。我曾进行过一个非常奇怪的赌注,事实证明我赌对了:虽然扩散模型在某种程度上十分愚笨,却能产出令人惊艳的美丽图像。 Abhinav:关于规模化聊天机器人,我认为还需要很长时间,才会有数亿人与AI模型进行大量对话。现在有很多初创公司和企业不仅仅使用ChatGPT,还有角色创建等其他项目,让人惊叹的是,有多少人实际上正在与这些AI模型建立情感联系。我不认为自己会在去年的九、十月份预测到这一点。过去六个月间出现的拐点真的出乎意料。 Swyx:你认为它们会用来做什么,比如情感支持? Abhinav:其中一些用于情感支持,或只是作为朋友。孤独和心理健康问题是一个热门难题。如果你去那些社区的子版块,人们在谈论和思考自己的AI朋友和这些角色,这就像是科幻小说中的情节,我从未预料到这种情况会成为现实。 Swyx:AI领域最有趣的待解决问题是什么? Abhinav:我对能够在精确性和类似BF16/FP16这方面能够走多远感兴趣。 我好奇这些问题能否随着模型规模的扩大变得更易解决。相关论文显示,随着规模不断扩大,量化和剪枝可能会更加容易。所以,作为未来几年规模扩大的自然结果,我们也许会朝着使用四位或两位乃至二进制权重的方向发展。 Jonathan:我想以另一种方式了解我们能实现多小的模型,能以多高的效率开发出同等性能的模型。这是我整个博士期间研究的问题,某种意义上说,这也是我在 Mosaic 研究的问题。OpenAI已经向我们展示了一种获得这种令人难以置信能力的途径,即规模的扩大。但我希望这不是唯一的途径。我希望有很多其他方法也可以达到这一目标,通过更好的建模方法,更好的算法等。 虽然我不喜欢神经科学的比喻,但从某种意义上说,我们的存在和大脑证明了至少存在另一种方式来实现这种难以置信的能力,而无需万亿级的参数甚至天文数字的资金投入。所以我真的很好奇我们究竟能实现多小的模型?是否存在另一条路径来实现这些能力,而不必按照现有的方式?如果存在的话,希望能在Mosaic中找到答案。 Swyx:没错,我最感兴趣的一个事实是,人类大脑只需消耗30瓦的能量,而在这一点上,模型与其相差了多个数量级。 Abhinav:我认为,无法仅凭单独的GPU或其他工具来达到这一目标。 Alessio:目前有很多信息正在传播,比如人们应该如何思考人工智能?他们应该关注什么? Jonathan:保持平和。有些人过于看重炒作;有些人则非常悲观,对炒作反应强烈,或者在某种程度上对其表示否认。应保持平和,明白我们已经构建出了十分有用的工具。 但是我们还未构建出通用智能,个人而言,我们离这个目标还很遥远。因此,保持平和并遵循科学十分重要,这正是Mosaic AI为之努力的。我们试图专注于对人类有用的事物,希望创造一个更美好的世界。我们会竭尽全力,但尤为重要的是,我们将遵循科学,以数据为指导,通过实际成果而非空谈来实现这一目标。 Abhinav:我认为,在开放社区中进行研究是无可比拟的。在社区中,不仅有大量人关注你的模型,甚至还会对模型的问题以及改进方式提出意见。这种开放性的研究将是未来的发展方向,无论是为了保证我们的模型安全,还是为了深入研究这些AI模型在现实世界中的影响和后果。 转自:https://blog.csdn.net/OneFlow_Official/article/details/131971520 该文章在 2024/1/27 15:49:46 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886